3.2. Chunking Experiment#
There are multiple methods of ingestion, depending on the type of data. For example, unstructured data such as documents or web pages can be split into chunks and embedded into vectors, while structured data such as tables or databases can be summarized or converted into natural language. In our case, since we are working with text data, we will look into different chunking strategies.
Experiment Overview#
Topic |
Description |
|---|---|
📝 Hypothesis |
Exploratory hypothesis: “Can introducing a new chunking strategy improve system’s performance?” |
⚖️ Comparison |
We will compare MarkdownHeaderTextSplitter, MarkdownTextSplitter and semantic chunking strategy (SemanticChunker). |
🎯 Evaluation Metrics |
We will look at Accuracy and Cosine Similarity to compare the performance. |
📊 Data |
The data that we will use consists of code-with-engineering and code-with-mlops sections from Solution Ops repository. |
📊 Evaluation Dataset |
300 question-answer pairs generated from code-with-engineering and code-with-mlops sections from Solution Ops repository. See Generation QA Notebook for insights on how they were generated. |
Note
Our goal here is not to identify which chunking strategy is the “best” in general but rather to demonstrate how the choice of chunking may have a non-trivial impact on the ultimate outcome from the RAG solution.
Why does chunking matter?#
When processing data, splitting the source documents into chunks requires care and expertise to ensure the resulting chunks are small enough to be effective during fact retrieval but not too small so that enough context is provided during summarization.
Why do we even need to chunk? you may ask.
The models used to generate embedding vectors have maximum limits on the text fragments provided as input. For example, the maximum length of input text for the Azure OpenAI embedding models is 8,191 tokens. Given that each token is around 4 characters of text for common OpenAI models, this maximum limit is equivalent to around 6000 words of text. If you’re using these models to generate embeddings, it’s critical that the input text stays under the limit. Partitioning your content into chunks ensures that your data can be processed by the model used for indexing and queries.
In our workshop, we work with text documents. Refer to Types of Tet Splitters for an overview of supported options from LangChain.
Setup#
Import necessary libraries
%run -i ./pre-requisites.ipynb
import glob
from langchain_community.document_loaders import UnstructuredFileLoader
import os
import pandas as pd
import plotly.express as px
Let’s load the documents from Solution Ops Playbook (from code-with-engineering and code-with-mlops folders):
def load_documents_from_folder(paths) -> list[str]:
markdown_documents = []
for path in paths:
for file in glob.glob(path, recursive=True):
loader = UnstructuredFileLoader(file)
document = loader.load()
markdown_documents.append(document)
return markdown_documents
%%capture --no-display
import ntpath
paths = ["../data/docs/code-with-engineering/**/*.md","../data/docs/code-with-mlops/**/*.md"]
if os.name == "nt":
paths = [ntpath.normpath(path) for path in paths]
documents = load_documents_from_folder(
paths)
1. Markdown Header Text Splitter#
Overview#
In this approach we will leverage the fact that our documents are markdown files and we will consider that the markdown pages are well structured. Therefore, we will split using the markdown headers.
Example#
Let’s load LangChain’s MarkdownHeaderTextSplitter to split the text for us
from langchain.text_splitter import MarkdownHeaderTextSplitter
For example, if we want to split this markdown:
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly"
We can specify the headers to split on:
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
Let’s look at the output:
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
[Document(page_content='Hi this is Jim\nHi this is Joe', metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'})]
Chunk the data#
def create_chunks_md_headers(documents: list) -> list:
print("Creating chunks...")
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on, strip_headers=False)
chunk_id = 0
chunks = {
"chunkId": [],
"chunkContent": [],
"source": []
}
for document in documents:
current_chunks_text_list = markdown_splitter.split_text(
document[0].page_content)
for i, chunk in enumerate(current_chunks_text_list):
chunks['chunkId'].append(f"chunk{chunk_id}_{i}")
chunks['chunkContent'].append(chunk.page_content)
chunks['source'].append(document[0].metadata['source'])
chunk_id += 1
return chunks
chunks_with_md_headers = create_chunks_md_headers(
documents)
df_chunks_with_md_headers = pd.DataFrame(chunks_with_md_headers)
df_chunks_with_md_headers.head()
Creating chunks...
| chunkId | chunkContent | source | |
|---|---|---|---|
| 0 | chunk0_0 | Structure of a Sprint \nThe purpose of this d... | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 1 | chunk1_0 | Who We Are \nOur team, ISE (Industry Solution... | ../data/docs/code-with-engineering/ISE.md |
| 2 | chunk2_0 | Engineering Fundamentals Checklist \nThis che... | ../data/docs/code-with-engineering/ENG-FUNDAME... |
| 3 | chunk3_0 | ISE Code-With Engineering Playbook \nAn engin... | ../data/docs/code-with-engineering/index.md |
| 4 | chunk4_0 | Work Item ID \nFor more information about how... | ../data/docs/code-with-engineering/code-review... |
Analysis#
Let’s look at the distribution of lengths in the chunks.
We create a new colum called chunk_text_length which contains the length of the chunk_text column.
df_chunks_with_md_headers['chunk_text_length'] = df_chunks_with_md_headers['chunkContent'].apply(
lambda x: len(x.split()))
df_chunks_with_md_headers.head(10)
| chunkId | chunkContent | source | chunk_text_length | |
|---|---|---|---|---|
| 0 | chunk0_0 | Structure of a Sprint \nThe purpose of this d... | ../data/docs/code-with-engineering/SPRINT-STRU... | 468 |
| 1 | chunk1_0 | Who We Are \nOur team, ISE (Industry Solution... | ../data/docs/code-with-engineering/ISE.md | 263 |
| 2 | chunk2_0 | Engineering Fundamentals Checklist \nThis che... | ../data/docs/code-with-engineering/ENG-FUNDAME... | 793 |
| 3 | chunk3_0 | ISE Code-With Engineering Playbook \nAn engin... | ../data/docs/code-with-engineering/index.md | 357 |
| 4 | chunk4_0 | Work Item ID \nFor more information about how... | ../data/docs/code-with-engineering/code-review... | 325 |
| 5 | chunk5_0 | FAQ \nThis is a list of questions / frequentl... | ../data/docs/code-with-engineering/code-review... | 548 |
| 6 | chunk6_0 | Code Reviews \nDevelopers working on projects... | ../data/docs/code-with-engineering/code-review... | 111 |
| 7 | chunk7_0 | Inclusion in Code Review \nBelow are some poi... | ../data/docs/code-with-engineering/code-review... | 852 |
| 8 | chunk8_0 | Pull Requests \nChanges to any main codebase ... | ../data/docs/code-with-engineering/code-review... | 653 |
| 9 | chunk9_0 | Code Review Tools \nCustomize ADO \nTask boa... | ../data/docs/code-with-engineering/code-review... | 392 |
Let’s plot the distribution:
# fig = px.histogram(df_chunks_with_md_headers, x='chunk_text_length',
# title='Histogram of Chunk Text Length', nbins=80, marginal='box')
# fig.show()
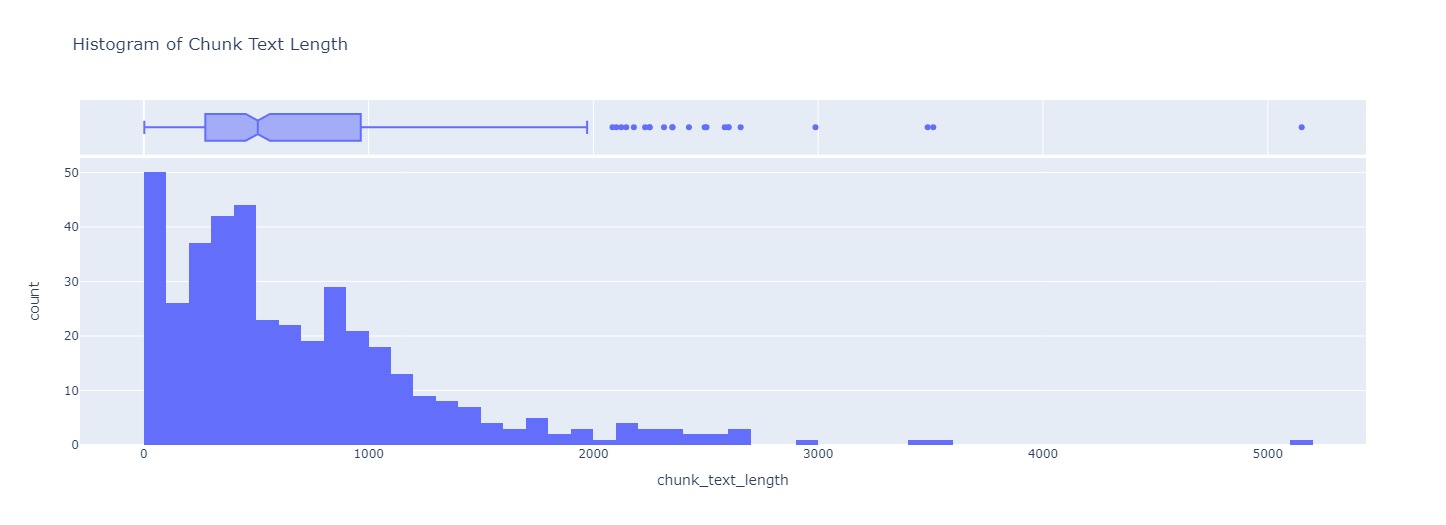
Note
In the interest of time, we have already chunked the data from Solution Ops repo using Markdown Header Text Splitter approach. The result can be found at md-header-text-splitter-engineering-mlops.json
2. Markdown Text Splitter using tiktoken encoder#
Overview#
To decide the length of each chunk, we will look at the distribution of the document lengths and the distribution of the chunk lengths. We will then decide on a chunk length that will give us a good distribution of chunk lengths. We will use a splitter that uses the tiktoken tokenizer to split the documents into chunks. Hence we do the following:
Tokenize all the documents, and look at the distribution of the document lengths
Based on the above distribution, decide on a chunk length
Split the documents into chunks of the decided length using MarkdownTextSplitter.from_tiktoken_encoder()
Example#
Let’s load LangChain’s MarkdownTextSplitter to split the text for us
from langchain.text_splitter import MarkdownTextSplitter
We can split a text via split_text function. Let’s take a sample text:
text = "This is the text I would like to chunk up. It is the example text for this exercise"
Let’s load up the text splitted. You need to specify the chunk overlap and chunk size
chunk_size = 5
chunk_overlap = 3
markdown_splitter = MarkdownTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size, chunk_overlap=chunk_overlap)
text = "This is the text I would like to chunk up. It is the example text for this exercise"
current_chunks_text_list = markdown_splitter.split_text(text)
current_chunks_text_list
['This is the text I',
'the text I would like',
'I would like to chunk',
'like to chunk up.',
'chunk up. It is',
'It is the example text',
'the example text for this',
'text for this exercise']
Chunk the data#
import ntpath
def load_md_documents_from_folder(path: str) -> list[str]:
print("Loading documents...")
data_documents = {
"solutionops_section": [],
"document_object": [],
"document_text": [],
"document_length": [],
"document_path": []
}
for path in paths:
for file in glob.glob(path, recursive=True):
loader = UnstructuredFileLoader(file)
document = loader.load()
data_documents["solutionops_section"].append(ntpath.normpath(file).split("\\")[3])
data_documents["document_object"].append(document)
data_documents["document_text"].append(document[0].page_content)
data_documents["document_length"].append(
len(document[0].page_content.split()))
data_documents["document_path"].append(file)
# markdown_documents.append(document)
return data_documents
%%capture --no-display
paths = ["../data/docs/code-with-engineering/**/*.md","../data/docs/code-with-mlops/**/*.md"]
if os.name == "nt":
paths = [ntpath.normpath(path) for path in paths]
markdown_documents = load_md_documents_from_folder(paths)
markdown_files = pd.DataFrame(markdown_documents)
markdown_files.head()
| solutionops_section | document_object | document_text | document_length | document_path | |
|---|---|---|---|---|---|
| 0 | code-with-engineering | [page_content='Structure of a Sprint\n\nThe pu... | Structure of a Sprint\n\nThe purpose of this d... | 468 | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 1 | code-with-engineering | [page_content='Who We Are\n\nOur team, ISE (In... | Who We Are\n\nOur team, ISE (Industry Solution... | 263 | ../data/docs/code-with-engineering/ISE.md |
| 2 | code-with-engineering | [page_content="Engineering Fundamentals Checkl... | Engineering Fundamentals Checklist\n\nThis che... | 793 | ../data/docs/code-with-engineering/ENG-FUNDAME... |
| 3 | code-with-engineering | [page_content='ISE Code-With Engineering Playb... | ISE Code-With Engineering Playbook\n\nAn engin... | 357 | ../data/docs/code-with-engineering/index.md |
| 4 | code-with-engineering | [page_content="Work Item ID\n\nFor more inform... | Work Item ID\n\nFor more information about how... | 325 | ../data/docs/code-with-engineering/code-review... |
Let’s look at the distribution of tokens in the chunks.
import tiktoken
encoding = tiktoken.get_encoding("cl100k_base")
markdown_files['tokens'] = markdown_files['document_text'].apply(
lambda x: encoding.encode(x))
markdown_files['n_tokens'] = markdown_files['tokens'].apply(
len)
# fig = px.histogram(markdown_files, x='n_tokens',
# title='Distribution of tokenization lengths', nbins=80, marginal='box')
# fig.show()
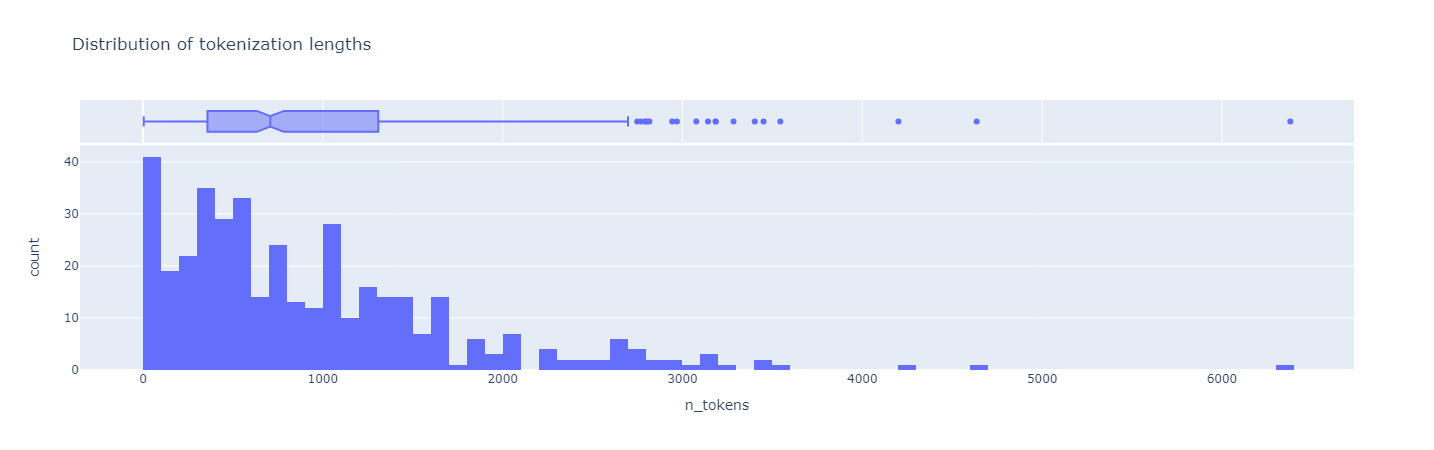
We decide to use chunk size = (quantile_1)/2 = 360/2 = 180 tokens. so that 75%+ of the documents will be represented by at least 2 chunks.
def create_chunks_tokens(documents: list) -> list:
markdown_splitter = MarkdownTextSplitter.from_tiktoken_encoder(
chunk_size=180, chunk_overlap=30
)
chunk_id = 0
chunks = {
"chunkId": [],
"chunkContent": [],
"source": []
}
for document in documents:
current_chunks_text_list = markdown_splitter.split_text(
document[0].page_content)
for i, chunk in enumerate(current_chunks_text_list):
chunks['chunkId'].append(f"chunk{chunk_id}_{i}")
chunks['chunkContent'].append(chunk)
chunks['source'].append(document[0].metadata['source'])
chunk_id += 1
return chunks
chunks_with_tokens = create_chunks_tokens(
markdown_files["document_object"])
Analysis#
df_chunks_with_tokens = pd.DataFrame(chunks_with_tokens)
df_chunks_with_tokens.head()
| chunkId | chunkContent | source | |
|---|---|---|---|
| 0 | chunk0_0 | Structure of a Sprint\n\nThe purpose of this d... | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 1 | chunk0_1 | [ ] Build a Product Backlog\n\nSet up a projec... | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 2 | chunk0_2 | Design the first test cases\n\n[ ] Decide on b... | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 3 | chunk0_3 | Day 3\n\n[ ] Agree on code style and on how to... | ../data/docs/code-with-engineering/SPRINT-STRU... |
| 4 | chunk0_4 | [ ] Agree on how to Design a feature and condu... | ../data/docs/code-with-engineering/SPRINT-STRU... |
Let’s look at the distribution of lengths in the chunks.
df_chunks_with_tokens['chunk_text_length'] = df_chunks_with_tokens['chunkContent'].apply(
lambda x: len(x.split()))
# fig = px.histogram(df_chunks_with_tokens, x='chunk_text_length',
# title='Histogram of Chunk Text Length', nbins=80, marginal='box')
# fig.show()
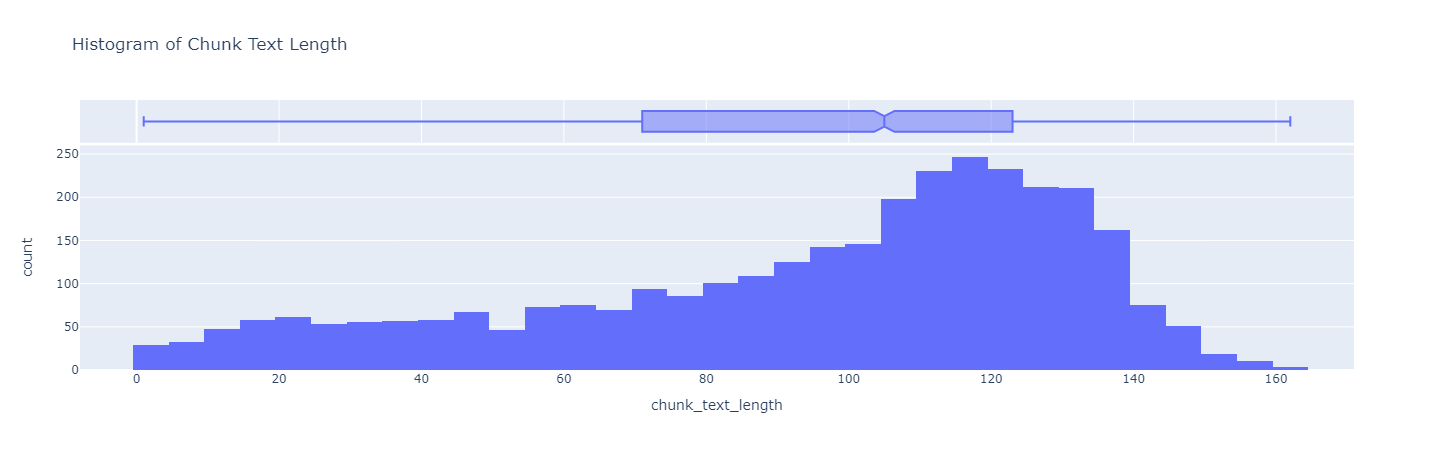
Note
In the interest of time, we have already chunked the data from Solution Ops repo using Markdown Text Splitter using tiktoken encoder approach. The result can be found at fixed-size-chunks-engineering-mlops-180-30.json.json
3. Semantic Chunking#
Overview#
In the previous approach, we chose a constant value for chunk size, in a random way. We did not leverage the actual content of the document, the structure, etc. In this section, we will look at Semantic Chunking from LangChain. This approach splits the text based on semantic similarity.
For insights on what it is doing, you can have a look at Level 4. Semantic Splitting.
Example#
%run -i ./pre-requisites.ipynb
from langchain_openai.embeddings import AzureOpenAIEmbeddings
from langchain_experimental.text_splitter import SemanticChunker
embeddings = AzureOpenAIEmbeddings(
azure_deployment="embeddings-model",
openai_api_version="2023-05-15",
api_key=azure_openai_key
)
with open("../data/docs/code-with-dataops/capabilities/analytical-systems/data-ingestion/batch-stream-ingestion/index.md") as f:
state_of_the_union = f.read()
text_splitter = SemanticChunker(embeddings)
docs = text_splitter.create_documents([state_of_the_union])
print(docs[1].page_content)
This group is either determined by a specific time interval or a certain size limit. Stream ingestion deals with continuous, unbounded datasets. That said, most of the current stream ingestion approaches use mini-batches to ingest data as it reduces the number of I/O operations. ## Batch Ingestion
Traditionally data ingestion has been done in batches due to the limitations of the legacy systems. It still remains a popular way to ingest data for the simplicity of its implementation. Almost every ETL tool supports batch ingestion. ### Batch Ingestion Architectural Patterns
#### Pull
Most batch ingestion data pipelines will connect to a source system and pull data from it at regular interval. There are two common patterns for a batch job to load data from a source system, full load and delta load. - _Full load_: The job will load all the records from the source table. - _Delta load_: The job will load only the new records added since the last execution of the job. For this approach to work, the source table needs to have a watermark column. ##### Azure Blob Storage Change Feed
When the data source is Azure Blob Storage, the [Change Feed feature](https://learn.microsoft.com/azure/storage/blobs/storage-blob-change-feed) implements batch pull ingestion for either the full load or delta load scenarios. The Change Feed provides transactional logs of all the changes that occur to the blobs and the blob metadata inside of a storage account, in an efficient and scalable manner. {% if extra.ring == 'internal' %}
The following repo provides a generic example for how to use the blob storage change feed in a batch ingestion process. [Azure Blob Storage Change Feed - Example](https://github.com/commercial-software-engineering/blob-storage-change-feed)
{% endif %}
#### Push
Though pull-based model for data ingestion is the most fault tolerant model, its biggest drawback is lack of real-time information. The push-based model aims to solve the problem as the source system sends data to the target as soon as the data is generated.
Note
In the interest of time, we have already chunked the data from Solution Ops repo using Semantic Chunking approach. The result can be found at semantic-chunks-engineering-mlops.json
📈 Evaluation#
In this workshop, to separate our experiments, we will take the Full Reindex strategy and we will create a new index per chunking strategy.
Therefore, for each chunking strategy we will:
Create a new index. Note: make sure to give a relevant name.
Embed the chunks that have been previously created. Note: In this experiment we are using AOI embedding model.
Populate the index with chunks.
Note
In the interest of time, we have already embedded the chunks using OAI embedding model:
The pre-generated embeddings for Markdown Header Text Splitter can be found at fixed-size-chunks-180-30-engineering-mlops-ada.json
The pre-generated embeddings for Markdown Text Splitter using tiktoken encode can be found at md-header-text-splitter-engineering-mlops-embedded-ada
The pre-generated embeddings for Semantic Chunking approach can be found at: semantic-chunks-engineering-mlops-embedded-ada.json
%%capture --no-display
%run -i ./helpers/search.ipynb
%run -i ./pre-requisites.ipynb
Let’s load the path to each embedded chunks. Note the name of variables:
%run -i ./pre-requisites.ipynb
print(f"Pre-generated embeddings for Markdown Header Text Splitter: {pregenerated_fixed_size_chunks_embeddings_ada}")
print(f"Pre-generated embeddings for Markdown Text Splitter using tiktoken encode: {pregenerated_markdown_header_chunks_embeddings_ada}")
print(f"Pre-generated embeddings for Semantic Chunks Splitter: {pregenerated_semantic_chunks_embeddings_ada}")
Pre-generated embeddings for Markdown Header Text Splitter: ./output/pre-generated/embeddings/fixed-size-chunks-180-30-engineering-mlops-ada.json
Pre-generated embeddings for Markdown Text Splitter using tiktoken encode: ./output/pre-generated/embeddings/md-header-text-splitter-engineering-mlops-embedded-ada.json
Pre-generated embeddings for Semantic Chunks Splitter: ./output/pre-generated/embeddings/semantic-chunks-engineering-mlops-embedded-ada.json
Note
You can reuse available functions from ./helpers/search.ipynb, such as: create_index and upload_data.
Create 3 search indexes#
Sample code for creating a new index and uploading the data:
%run -i ./helpers/search.ipynb
# 1. Create the new index
index_name = "fixed-size-180-30"
embedding_path = pregenerated_fixed_size_chunks_embeddings_ada
create_index(index_name)
# Uncomment the following code when running the cell:
# # 3. Upload the embeddings to the new index
# upload_data(file_path=embedding_path, search_index_name=index_name)
Index: 'fixed-size-180-30' created or updated
%run -i ./helpers/search.ipynb
# 1. Create the new index
index_name = "semantic-chunking"
embedding_path = pregenerated_semantic_chunks_embeddings_ada
create_index(index_name)
# 3. Upload the embeddings to the new index
upload_data(file_path=embedding_path, search_index_name=index_name)
Index: 'semantic-chunking' created or updated
Uploaded 1216 documents to Index: semantic-chunking
%run -i ./helpers/search.ipynb
# 1. Create the new index
index_name = "markdown-header-chunking"
embedding_path = pregenerated_markdown_header_chunks_embeddings_ada
create_index(index_name)
# 3. Upload the embeddings to the new index
upload_data(file_path=embedding_path, search_index_name=index_name)
Index: 'markdown-header-chunking' created or updated
Uploaded 407 documents to Index: markdown-header-chunking
📊 Evaluation Dataset#
Note: The evaluation dataset can be found at solution-ops-200-qa.json. The format is:
"user_prompt": "", # The question
"output_prompt": "", # The answer
"context": "", # The relevant piece of information from a document
"chunk_id": "", # The ID of the chunk
"source": "" # The path to the document, i.e. "..\\data\\docs\\code-with-dataops\\index.md"
Let us configure the path to evaluation dataset and reload environment variables
%run -i ./pre-requisites.ipynb
🎯Evaluation Metrics#
%run -i ./helpers/search.ipynb
from statistics import mean, median
import os
import numpy as np
from numpy.linalg import norm
Let’s define the evaluation metrics:
Cosine similarity: will calculate the similarity between the first retrieved chunk and the expected chunk. We will look at the average and mean cosine similarity across our evaluation dataset.
Accuracy: we will calculate how many times the system returned the expected document, and by document we mean the actual path to the markdown file.
def calculate_cosine_similarity(expected_document_vector, retrieved_document_vector):
cosine_sim = np.dot(expected_document_vector, retrieved_document_vector) / \
(norm(expected_document_vector)*norm(retrieved_document_vector))
return float(cosine_sim)
import ntpath
def calculate_metrics(evaluation_data_path, search_index_name, embedding_function=oai_query_embedding):
""" Evaluate the retrieval performance of the search index using the evaluation data set.
Args:
evaluation_data_path (str): The path to the evaluation data set.
embedding_function (function): The function to use for embedding the question.
search_index_name (str): The name of the search index to use for retrieval.
Returns:
list: The cosine similarities between the expected documents and the top retrieved documents.
"""
if not os.path.exists(evaluation_data_path):
print(f"The path to the evaluation data set {evaluation_data_path} does not exist. Please check the path and try again.")
return
nr_correctly_retrieved_documents = 0
nr_qa = 0
cosine_similarities = []
with open(evaluation_data_path, "r", encoding="utf-8") as file:
evaluation_data = json.load(file)
for data in evaluation_data:
user_prompt = data["user_prompt"]
expected_document = data["source"]
expected_document_vector = embedding_function(data["context"])
# 1. Search in the index
search_response = search_documents(
search_index_name=search_index_name,
input=user_prompt,
embedding_function=embedding_function,
)
retrieved_documents = [ntpath.normpath(response["source"])
for response in search_response]
top_retrieved_document = search_response[0]["chunkContentVector"]
# 2. Calculate cosine similarity between the expected document and the top retrieved document
cosine_similarity = calculate_cosine_similarity(
expected_document_vector, top_retrieved_document)
cosine_similarities.append(cosine_similarity)
# 3. If the expected document is part of the retrieved documents,
# we will consider it correctly retrieved
if ntpath.normpath(expected_document) in retrieved_documents:
nr_correctly_retrieved_documents += 1
nr_qa += 1
accuracy = (nr_correctly_retrieved_documents / nr_qa)*100
print(f"Accuracy: {accuracy}% of the documents were correctly retrieved from Index {index_name}.")
return cosine_similarities
👩💻 1. Evaluate the Markdown Header Text Splitter - took 3 min#
🔍 Code. It may take up to 3 minutes:
# TODO: Replace this with the name of the index you want to evaluate
index_name = "markdown-header-chunking"
cosine_similarities = calculate_metrics(
evaluation_data_path=path_to_evaulation_dataset,
search_index_name=index_name,
)
avg_score = mean(cosine_similarities)
print(f"Avg score:{avg_score}")
median_score = median(cosine_similarities)
print(f"Median score: {median_score}")
👩💻 2. Evaluate the Markdown Text Splitter using tiktoken encode#
Note: It’s equivalent to the first experiment.
🔍 Code. It may take up to 3 minutes:
# TODO: Replace this with the name of the index you want to evaluate
index_name = "fixed-size-180-30"
cosine_similarities = calculate_metrics(
evaluation_data_path=path_to_evaulation_dataset,
search_index_name=index_name,
)
avg_score = mean(cosine_similarities)
print(f"Avg score:{avg_score}")
median_score = median(cosine_similarities)
print(f"Median score: {median_score}")
👩💻 3. Evaluate the semantic chunking strategy#
🔍 Code. It may take up to 3 minutes:
# TODO: Replace this with the name of the index you want to evaluate
index_name = "semantic-chunking"
cosine_similarities = calculate_metrics(
evaluation_data_path=path_to_evaulation_dataset,
search_index_name=index_name,
)
avg_score = mean(cosine_similarities)
print(f"Avg score:{avg_score}")
median_score = median(cosine_similarities)
print(f"Median score: {median_score}")
💡 Conclusions#
Take few moments to analyse the results.
🔍 Pre-calculated results:

In terms of cosine similiraty, all strategies got a good score. However, the “Markdown Text splitter” got the highest one. In terms of accuracy, the markdown header text splitter is falling behind with only 63% accuracy. The Semantic chunker has a reasonable accuracy of 70%, but is far behind the “Markdown text splitter” one. That is a surprising result, as intuitively, we would have expected the semantic chunking strategy got the highest score.
In reality, the results of “Markdown Text splitter” are better than it probably is in practice. Can you guess why?
… In practice, the evaluation dataset is ideally created and curated by subject-matter human experts. In this workshop, we have created synthetic data … using the markdown text splitter chunking strategy, so the results above are inherently biased. If one were to regenerate the data, one should consider to create question/answer pairs on a whole document rather than chunking every document.